Data Engineering
End-to-end data pipelines from schema normalization to multi-system integration at enterprise scale
Eliminate manual data quality checks and integration bottlenecks with intelligent data systems. Our solutions combine schema normalization across 300+ tables, cross-system validation engines, ETL pipelines processing millions of records, and API layers connecting legacy systems to modern platforms—delivering $8M+ in saved costs and 5× throughput improvements.
Problems We Solve
Challenge
Inconsistent data across TE, GL, Payroll, HRIS creating reconciliation nightmares
Our Solution
Cross-system validation engines processing 300+ tables with schema normalization and exception handling saving $8M+
Challenge
Data trapped in silos across CRM, ERP, legacy systems blocking automation
Our Solution
Real-time bidirectional sync with custom API layers, conflict resolution, and data lineage tracking
Challenge
Multi-format data ingestion (PDFs, Excel, legacy files) creating throughput bottlenecks
Our Solution
Scalable ETL pipelines with VLM + OCR processing achieving 5× indexing throughput improvements
Our Approach
Data Landscape Mapping & Requirements Discovery
Document your data flows, systems, validation rules, and integration requirements. We map data lineage across TE, GL, Payroll, HRIS, and legacy systems to identify critical validation checkpoints and API needs.
Schema Design & Validation Engine Construction
Build deterministic validation engines with configurable rules, schema normalization, and data type conversions. We develop robust ETL pipelines, API layers for legacy systems, and automated reconciliation logic.
Pipeline Deployment & Integration Testing
Deploy multi-agent orchestration coordinating SQL validation, flat-file processing, and cross-system sync. Comprehensive testing including edge cases, failure scenarios, and data consistency validation.
Monitoring, Optimization & Continuous Improvement
Implement real-time dashboards showing pass/fail rates, error distributions, throughput metrics, and SLA compliance. We optimize pipeline performance, refine validation rules, and scale to additional data sources.
Technology Stack
Proven Results
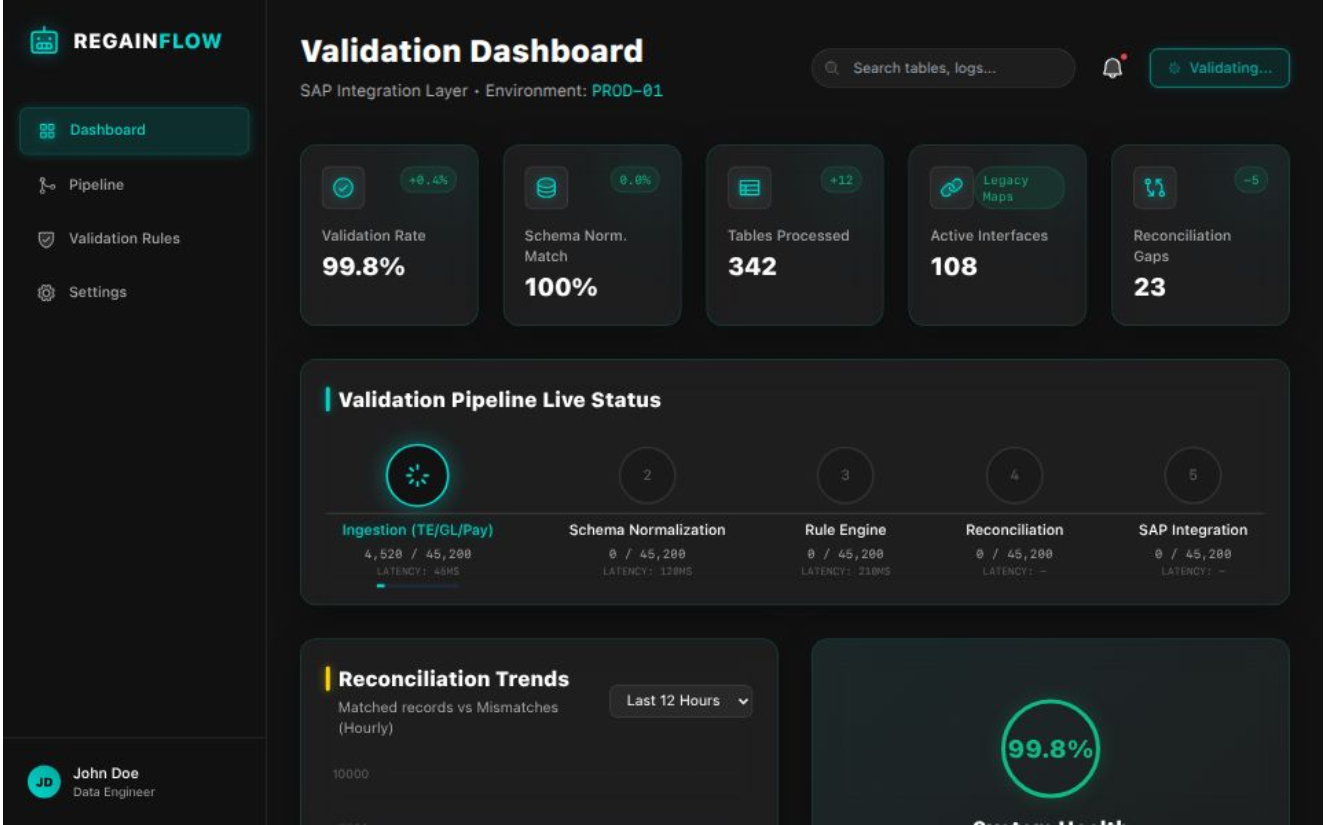
HCM Interoperability Platform
End-to-end validation pipeline across TE, GL, Payroll, and HRIS systems. Schema normalization, deterministic rule engines, and reconciliation logic spanning 300+ tables and over 100 legacy interfaces mapped and validated against the modernized SAP integration layer.
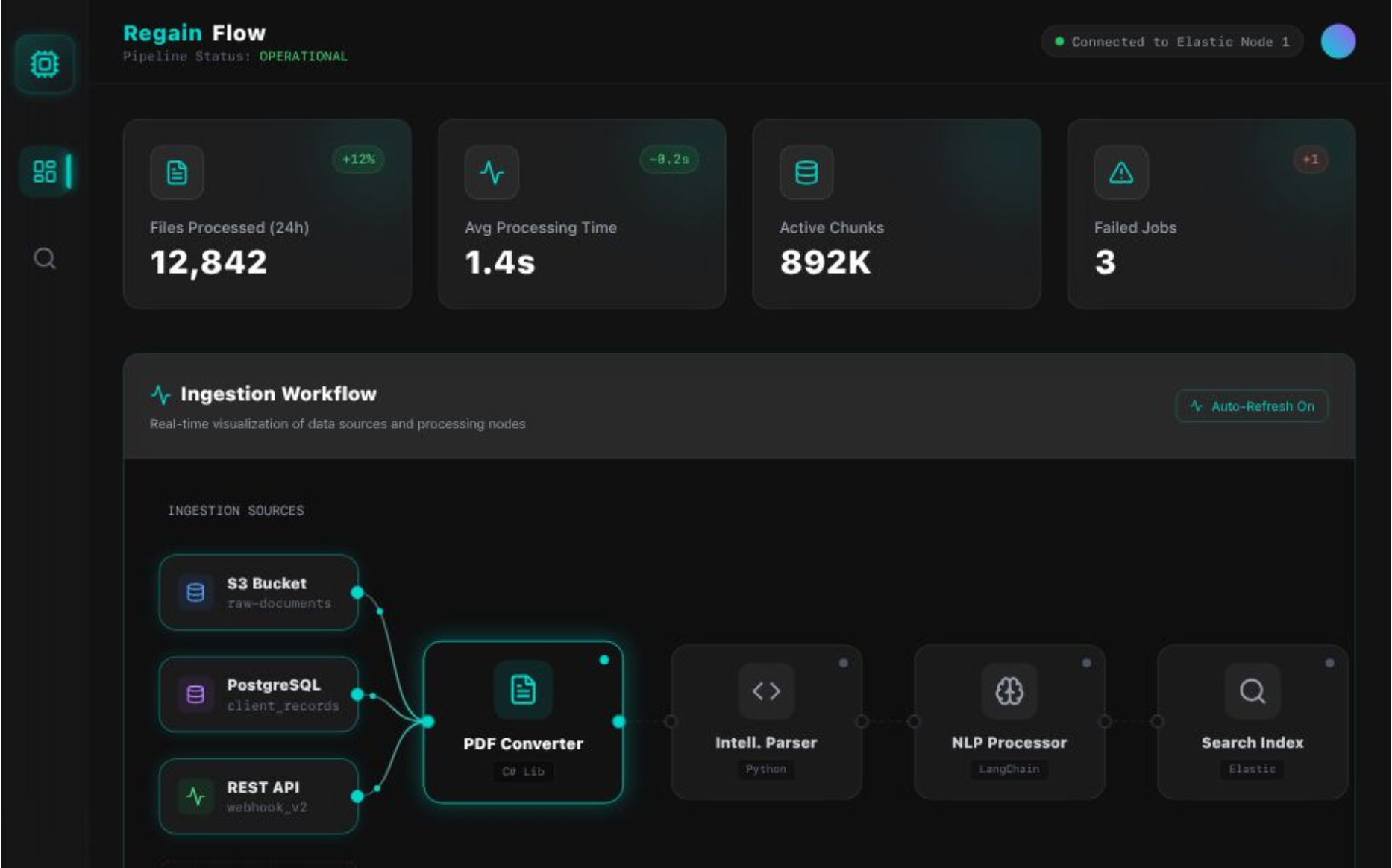
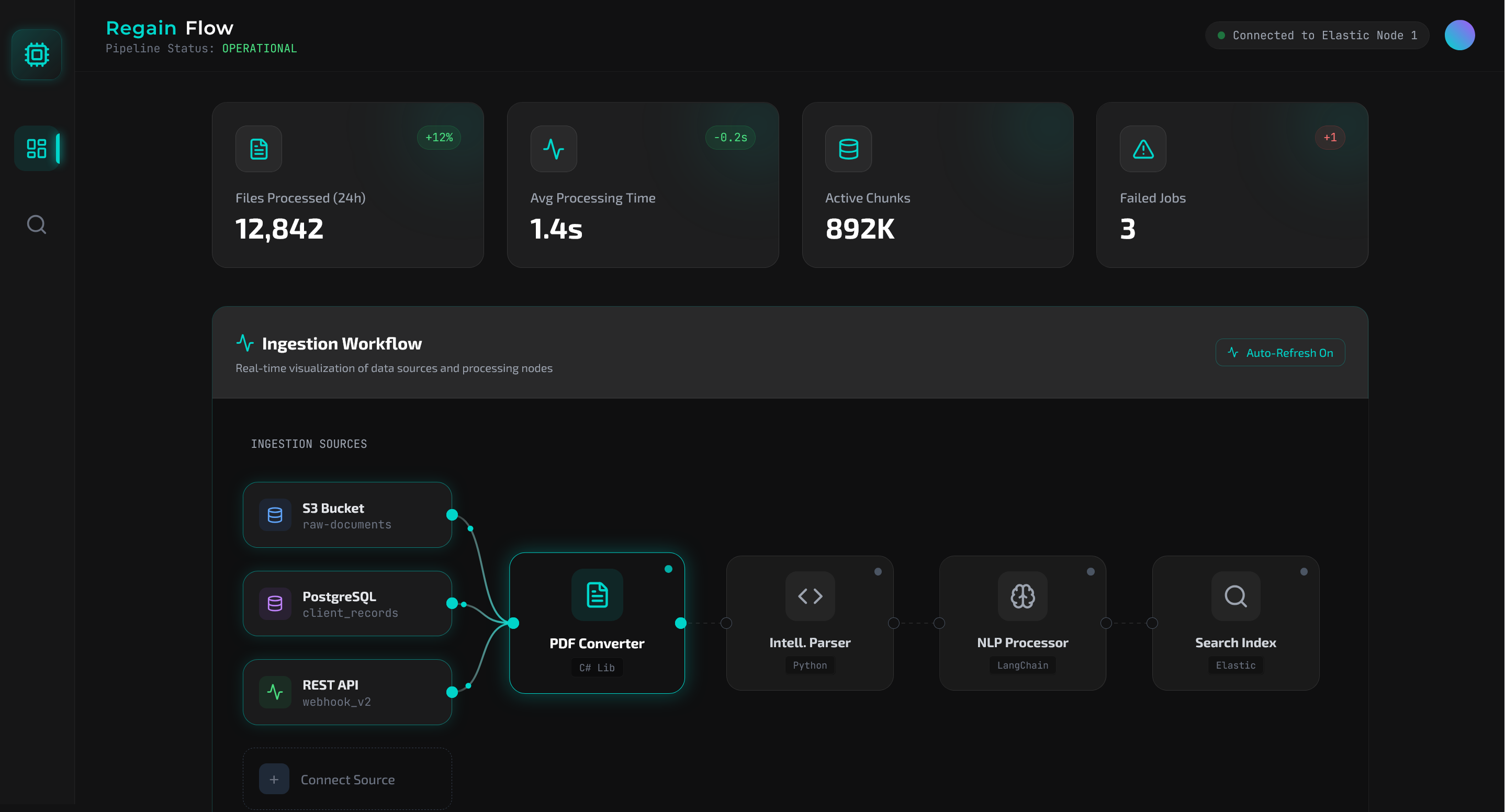
Multi-Format Engineering ETL Pipeline
We created a C# backend that loads many file types, converts them to PDFs, sends them to a Python parser that extracts text, chunks content, summarizes tables, and then indexes the processed data into Elasticsearch so engineering teams can search it quickly.
Legacy RPA Modernization with Python & LangGraph
Converted Blue Prism legacy automations into modern Python workflows with multi-agent AI orchestration. Eliminated licensing costs, improved reliability, and reduced multi-hour processes to minutes.
Transform Your Data Infrastructure
Schedule a free consultation to discuss your data challenges. We'll map your validation needs, integration requirements, and design scalable data systems proven to save millions.